| HOME | HELP | �V�K�쐬 | �V���L�� | �c���[�\�� | �X���b�h�\�� | �g�s�b�N�\�� | �t�@�C���ꗗ | ���� | �ߋ����O |
| HOME | HELP | �V�K�쐬 | �V���L�� | �c���[�\�� | �X���b�h�\�� | �g�s�b�N�\�� | �t�@�C���ꗗ | ���� | �ߋ����O |
| ||||
747�~531 => 250�~177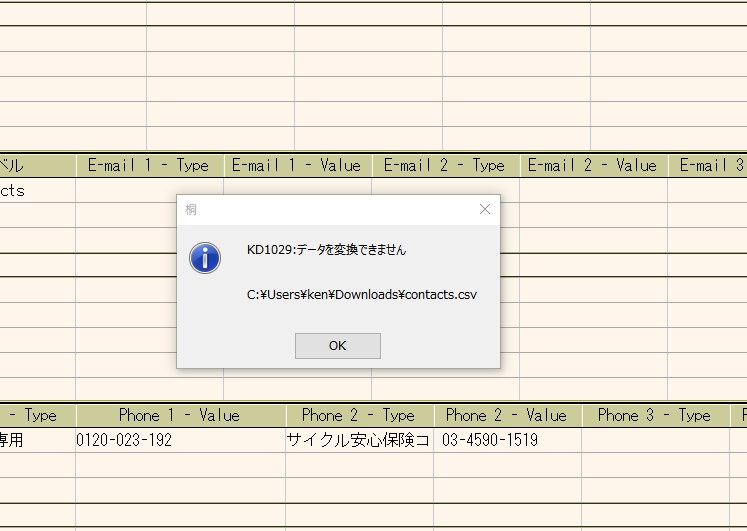 20260129_0245.jpg/66KB | ||||
| ||||
�����ς�! | ||||
| ||||
| ���̃X���b�h�ɏ������� |
|---|
| HOME | HELP | �V�K�쐬 | �V���L�� | �c���[�\�� | �X���b�h�\�� | �g�s�b�N�\�� | �t�@�C���ꗗ | ���� | �ߋ����O |