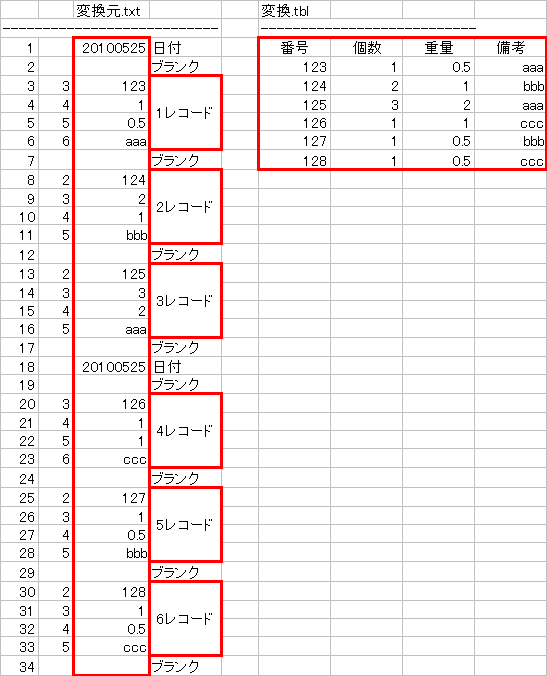
| 「5行を1レコード」の一括処理ではありませんが、データの並びに規則性があれば考え方は同じはず。本人は『変換後は日付は必要ございません。』と言っているにも関わらず、日付項目まで追加した一括処理です。(そんなに変化ないんですが^^;)
いずれもtxtを作業表に読み込んでの処理です。
※一部Kanasy.Geさんのパクリあり
■印字コマンド版
変数宣言 固有,数値{&i},文字列{&日付,&番号,&個数,&重量,&備考}
ファイル名入力 初期値="トンタ元*.txt", プロンプト="読み込むTXTファイルを指定",&選択ファイル名
条件(&選択ファイル名="") 終了
表 "トンタ元.tbl"
行削除 *,圧縮
読み込み テキスト,&選択ファイル名
印字開始 "トンタ変換.txt"
繰り返し (.not #EOF)
&日付=#部分列([TXT],1,4)+"/"+#部分列([TXT],5,2)+"/"+#部分列([TXT],7,2)
ジャンプ 行番号=+2
繰り返し &i=1,3
&番号=[TXT]
ジャンプ 行番号=次行
&個数=[TXT]
ジャンプ 行番号=次行
&重量=[TXT]
ジャンプ 行番号=次行
&備考=[TXT]
印字 &日付,",",&番号,",",&個数,",",&重量,",",&備考
ジャンプ 行番号=+2
繰り返し終了
繰り返し終了
印字終了
表 "トンタ変換.tbl"
ジャンプ 行番号=終端
読み込み テキスト,"トンタ変換.txt",区切り=","
表形式編集
■行追加版
変数宣言 固有,数値{&i},文字列{&日付,&番号,&個数,&重量,&備考}
ファイル名入力 初期値="トンタ元*.txt", プロンプト="読み込むTXTファイルを指定",&選択ファイル名
条件(&選択ファイル名="") 終了
表 "トンタ変換.tbl"
表 "トンタ元.tbl"
編集表 "トンタ元.tbl"
行削除 *,圧縮
読み込み テキスト,&選択ファイル名
繰り返し (.not #EOF)
&日付=#部分列([TXT],1,4)+"/"+#部分列([TXT],5,2)+"/"+#部分列([TXT],7,2)
ジャンプ 行番号=+2
繰り返し &i=1,3
&番号=[TXT]
ジャンプ 行番号=次行
&個数=[TXT]
ジャンプ 行番号=次行
&重量=[TXT]
ジャンプ 行番号=次行
&備考=[TXT]
編集表 "トンタ変換.tbl"
行追加 [日付]=#日時値(&日付),[番号]=#数値(&番号),[個数]=#数値(&個数),[重量]=#数値(&重量),[備考]=&備考
編集表 "トンタ元.tbl"
ジャンプ 行番号=+2
繰り返し終了
繰り返し終了
編集表 "トンタ変換.tbl"
表形式編集
|